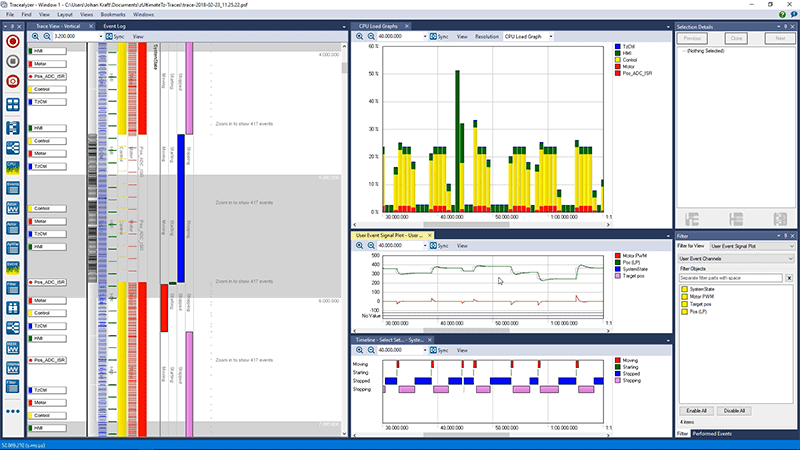
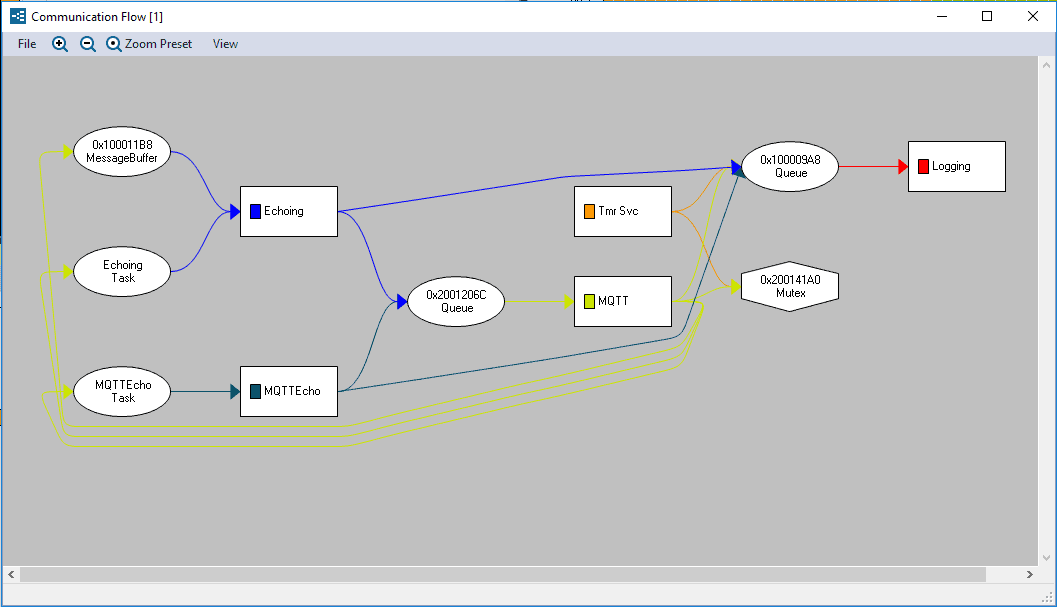
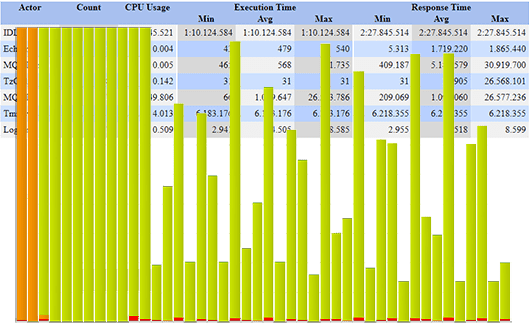
One of the biggest problems in embedded development today is understanding what a software stack or demo that you didn’t write is doing. In this post, we’ll examine how we can find this out using the Tracealyzer communication flow diagram.
Quite a few embedded software developers don’t know whether their applications meet their timing requirements. In today’s Tracealyzer Hands On post, we will explore how to use Tracealyzer to verify task timing and scheduling.
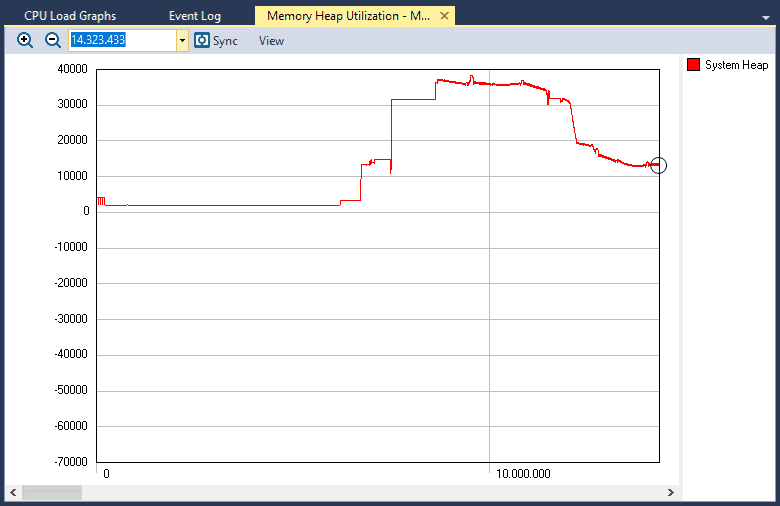
Have you ever seen your embedded system behave strangely and had that sinking feeling that you might have a memory leak? Tracealyzer offers several different methods to detect memory leaks.
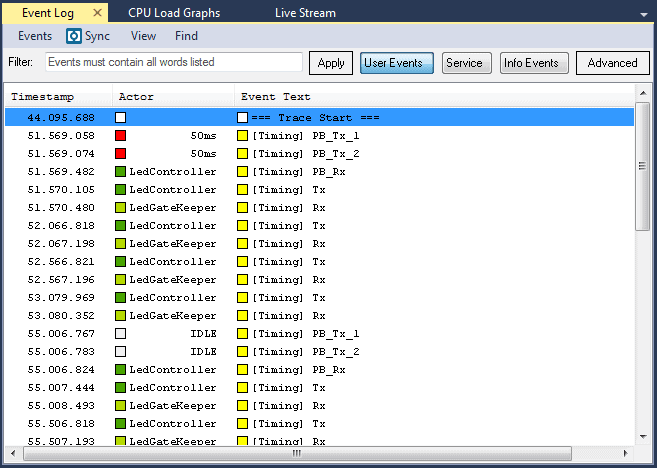
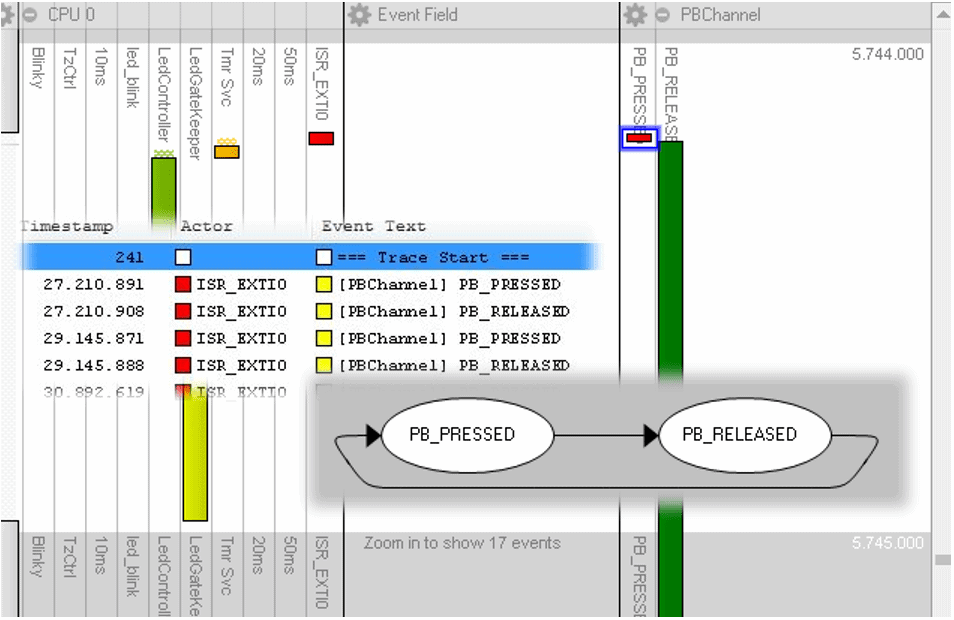
What if you want to visualize some application data in Tracealyzer, measure the time between two events or monitor a state machine? In this post, we will show how you can set up this kind of custom logging.
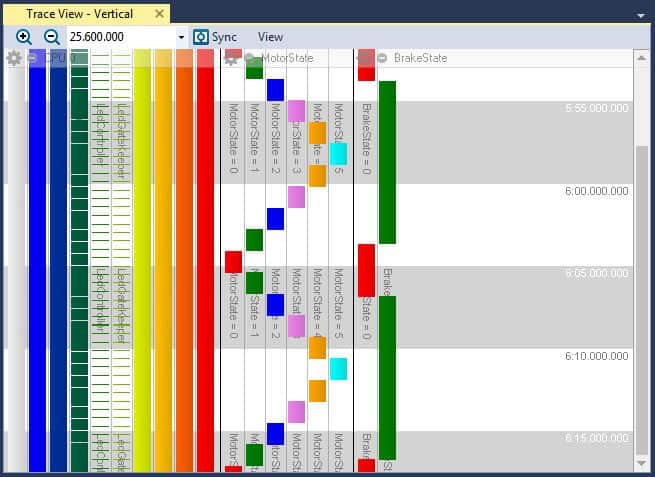
In the previous Hands On post we introduced the concept of intervals, which is the time between any two events and can be added to the timeline. In this post, we will take the interval one step further and see how we can use Tracealyzer to monitor state machines.
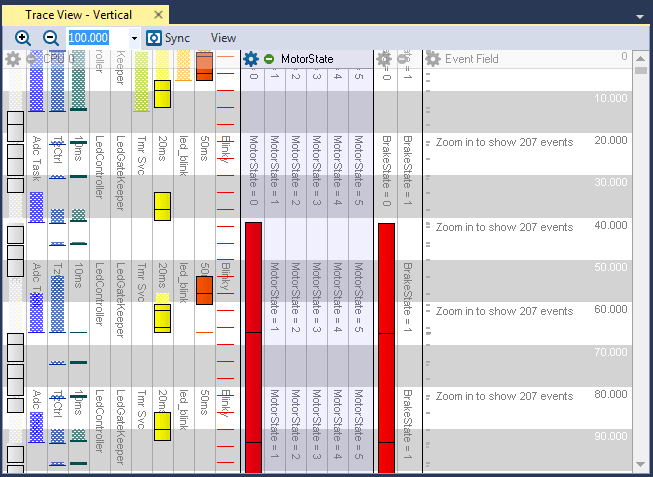
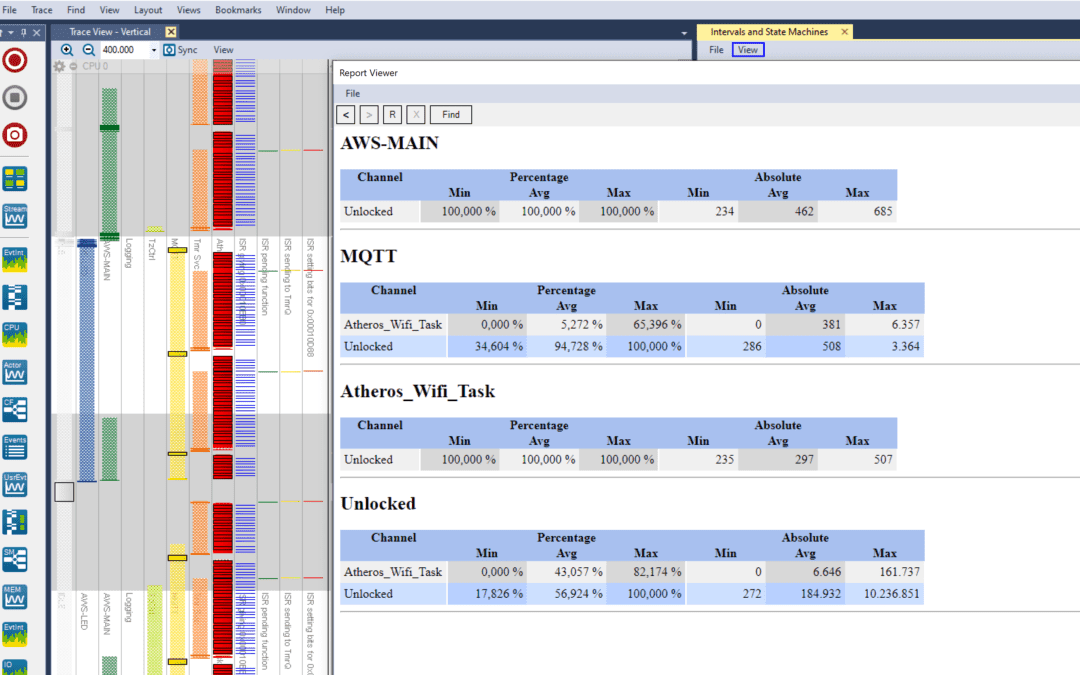
In this post, we visualise the custom interval and state machine information available in Tracealyzer and explore how we can use it to better understand our application.
Within Tracealyzer’s trace view, tasks, events and state machines are now organized into view fields, collections of tasks, intervals or events. In this post, we are going to examine how you can use those views to simplify working with Tracealyzer.
We have had a few customers asking us if they can use Tracealyzer to detect when a task holds two mutexes at the same time. The answer is yes, there are in fact several ways you can do this.
We serve cookies. If you think that's ok, just click "Accept all". You can also choose what kind of cookies you want by clicking "Settings".
Read our cookie policy